As an undergraduate with a keen interest in computer vision, I found myself fascinated by the subject of digital image processing, particularly Content-Based Image Retrieval (CBIR). When my professor encouraged me to work on a project of my choice, I eagerly delved into the fascinating field of digital image processing beyond the standard lab exercises. While my peers were focused on their routine lab work, I was immersed in the world of CBIR. In this blog post, I will share the knowledge I gained, from conventional methods to state-of-the-art neural networks. I'll also discuss how these techniques can help you find the right image every time. So join me on an enlightening journey as I reveal what I've learned!

It is important to emphasize that the primary goal of all content-based image retrieval techniques is to transform images into numerical representations, typically in the form of n-dimensional vectors. This allows us to compare and manipulate images using mathematical operations. By using various distance metrics and clustering algorithms, we can assess the similarity between images and categorize them into relevant groups.
The code for my experiments can be found at https://github.com/pcktm/image-retrieval-experiments, and I wholeheartedly encourage you to check it out and explore the fascinating world of image retrieval!
Classical methods
I decided to start with the classical methods of CBIR, which were invented in the early days of digital image processing in the 1990s and early 2000s. These methods are based on extracting global features from images, such as color, texture, and other statistics. Global features represent the overall characteristics of an image and can be used to describe and compare images. Some of the most common global features used in classical CBIR methods are color histograms, texture features based on Gabor filters, and statistical features such as mean, variance, and entropy.
Excited to get started on my project, I began by following an "Content-based image retrieval tutorial" by Joani Mitro. The report covered classic CBIR techniques such as color histogram quantization and RGB means and moments, which I was able to implement with ease. However, I hit a roadblock when it came to the next step: implementing a color auto-correlogram.

A color auto-correlogram is a powerful technique invented by Huang, J., Ravi Kumar, S., Mitra, M. et al. in their seminal paper, "Spatial Color Indexing and Applications" published back in 1999. In short, a color auto-correlogram is a tool that allows us to measure the spatial correlation between color values in an image. For example, if we compute the color auto-correlogram for a given image and find that the value for the red-blue pair is high, this indicates that red is likely to be found near blue in the image. This information can be used to identify other images that have similar color patterns and texture characteristics.
The problem was that when it was time for implementation of the color auto-correlogram, I quickly found that the only implementation available was in MATLAB. Unfortunately, I was working on this project in Python using OpenCV2, and I had no knowledge of MATLAB. This left me with the monumental job of rewriting the entire algorithm in Python.
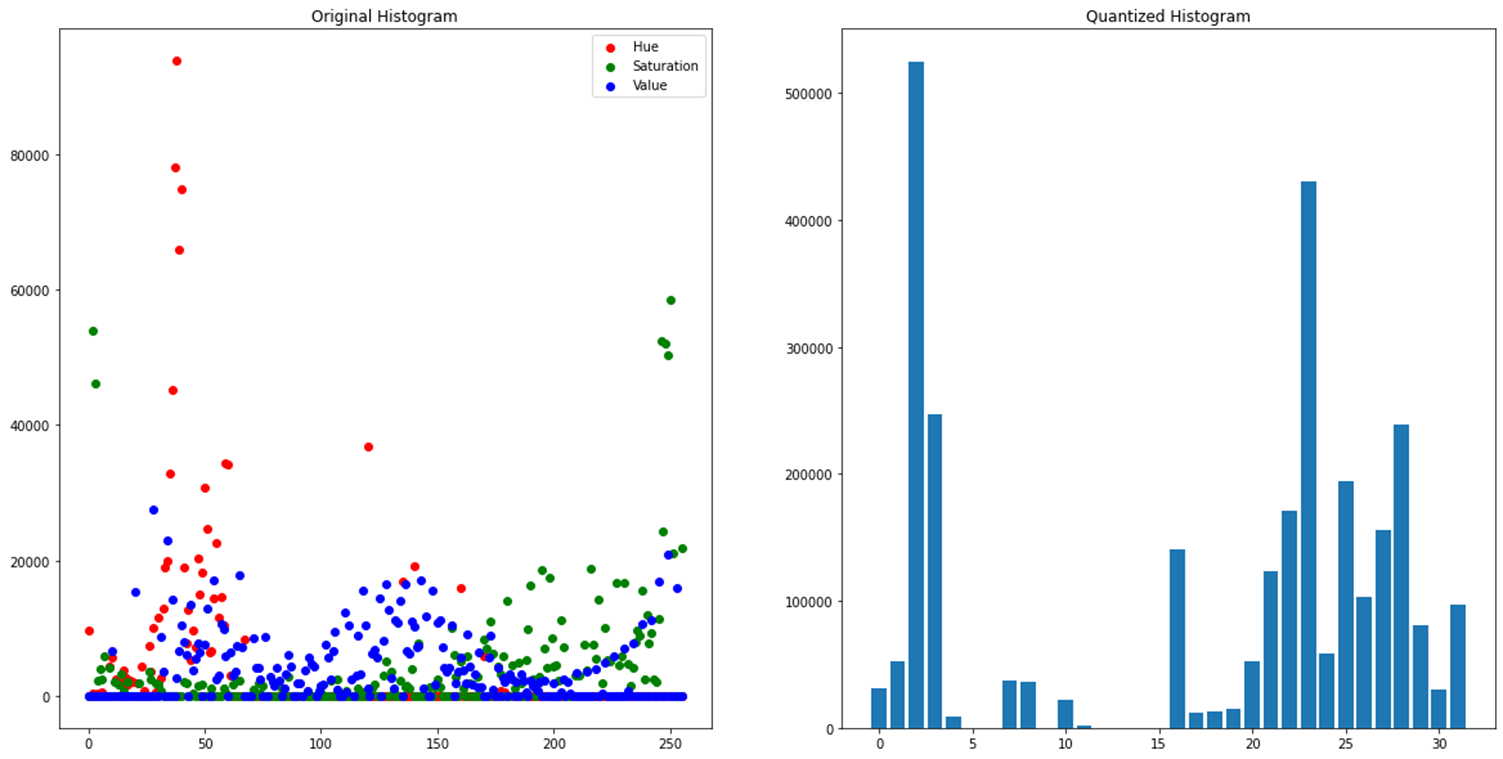
It took literally days of hard work and countless hours of debugging, but I finally got it to almost work with the help of Copilot at one point, except instead of a vector of 512 values, I got a vector of insane size. After digging around, I found that MATLAB has a function that palletizes the image to just 64 colors. Unfortunately, OpenCV2 has no equivalent, and I couldn't just trim the least significant bits or use k-means clustering to create a palette for each image, because the resulting vectors wouldn't be comparable across images.
After some trial and error, I finally came up with a solution: I took a PNG image of the Windows 2000 or something color palette and used it to palletize all my images. And finally, it clicked! The search began to work, and I was able to retrieve images that had a similar color distribution to mine!
Now, let's put these extracted features to work by testing different distance metrics and searching for images in the flickr30k dataset using a single global feature vector that combines all of them. Here are some of the results:


Local features based methods
Next, I delved into local feature-based methods, specifically examining the SIFT and ORB keypoint detectors and descriptor generators. I chose these algorithms because they are seamlessly integrated into OpenCV2 and quite easy to use, making them ideal for what I wanted to explore.

The bag-of-words approach is a popular method for representing local features in image retrieval. It involves clustering local descriptors (in this case, SIFT or ORB descriptors) into a set of visual words using K-means clustering. A histogram-like representation of the image is then created by assigning each descriptor to the nearest visual word. These histograms are called Bag of Visual Words vectors, which can then be used for similarity searches using plain old distance metrics.
Okay, so the term Frequency - Inverse Document Frequency (TF-IDF) technique was originally invented for natural language processing, but it turns out that it can be just as useful for image applications! Essentially, TF-IDF is a weighting scheme that assigns weights to words in a text document based on how often they occur in that document and how often they occur across all documents in a corpus. In the context of image retrieval, we can think of an image as a "document" and the visual features as "words". By calculating the TF-IDF scores for each feature, we can identify the most "distinctive" features that are most likely to be useful in distinguishing one image from another.
To give an example of how IDF works, let's consider the visual word "sky". Imagine there are thousands of images containing the visual word "sky", but only a small percentage of those images contain another visual word "eye". If we use IDF weighting, the visual word "eye" will have a higher weight compared to "sky" because it is less common in the total set of images.
The whole algorithm looks like this:
- First, we extract local feature descriptors from the image (such as SIFT, SURF, or ORB). I personally use both SIFT and ORB at the same time.
- We then place all the descriptors into a K-means classifier and obtain n clusters.For each image, we calculate how many descriptors belong to each cluster, resulting in an n-dimensional Bag of Visual Words vector.
- We transform this Bag of Words vector into a TF-IDF vector, which we can use to measure the distance between images using any distance metric (such as cosine or Euclidean distance).
Again, here are some of the results on the flickr30k dataset:
 Despite SIFT and ORB not considering color information, the images are still similar.
Despite SIFT and ORB not considering color information, the images are still similar. Clearly the common visual element across these photos is "dots".
Clearly the common visual element across these photos is "dots".The biggest problem with CBIR
A notable challenge in content-based image retrieval is the scarcity of meaningful datasets. Many scientific articles tend to reduce the complexity of the problem by treating it as a classification problem, rather than focusing on measuring the similarity of image content. This raises important questions: How can we effectively evaluate the performance of our models? Which approach is better - classical methods or SIFT+ORB?
So I decided to simplify the problem to a classification task. To do this, I used the Landscapes dataset (which, as you'll soon find out, was not the most optimal choice). I assigned each image in the test set a category based on its 3 nearest neighbors from the training set, allowing me to evaluate the performance of the different techniques under this classification framework.
 Here are the results of using SIFT for searching in the landscape dataset.
Here are the results of using SIFT for searching in the landscape dataset. I may have inadvertently created a watermark detector!
I may have inadvertently created a watermark detector!Yeah... the dataset is of low quality which will have an impact on the accuracy. However, it's worth noting that the content of the images is actually very similar, which is exactly what we're looking for!
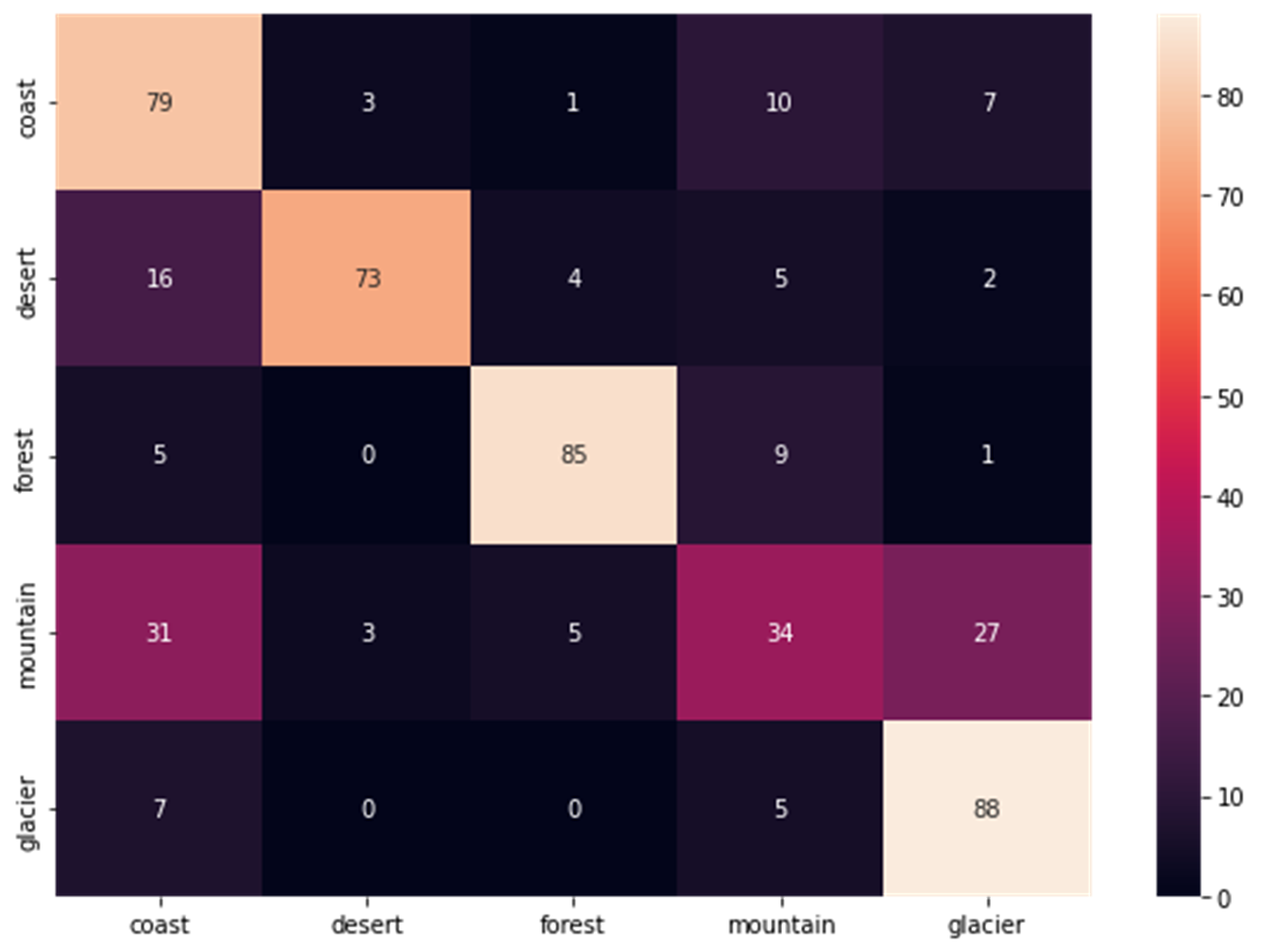 Confusion matrix for classical methods.
Confusion matrix for classical methods.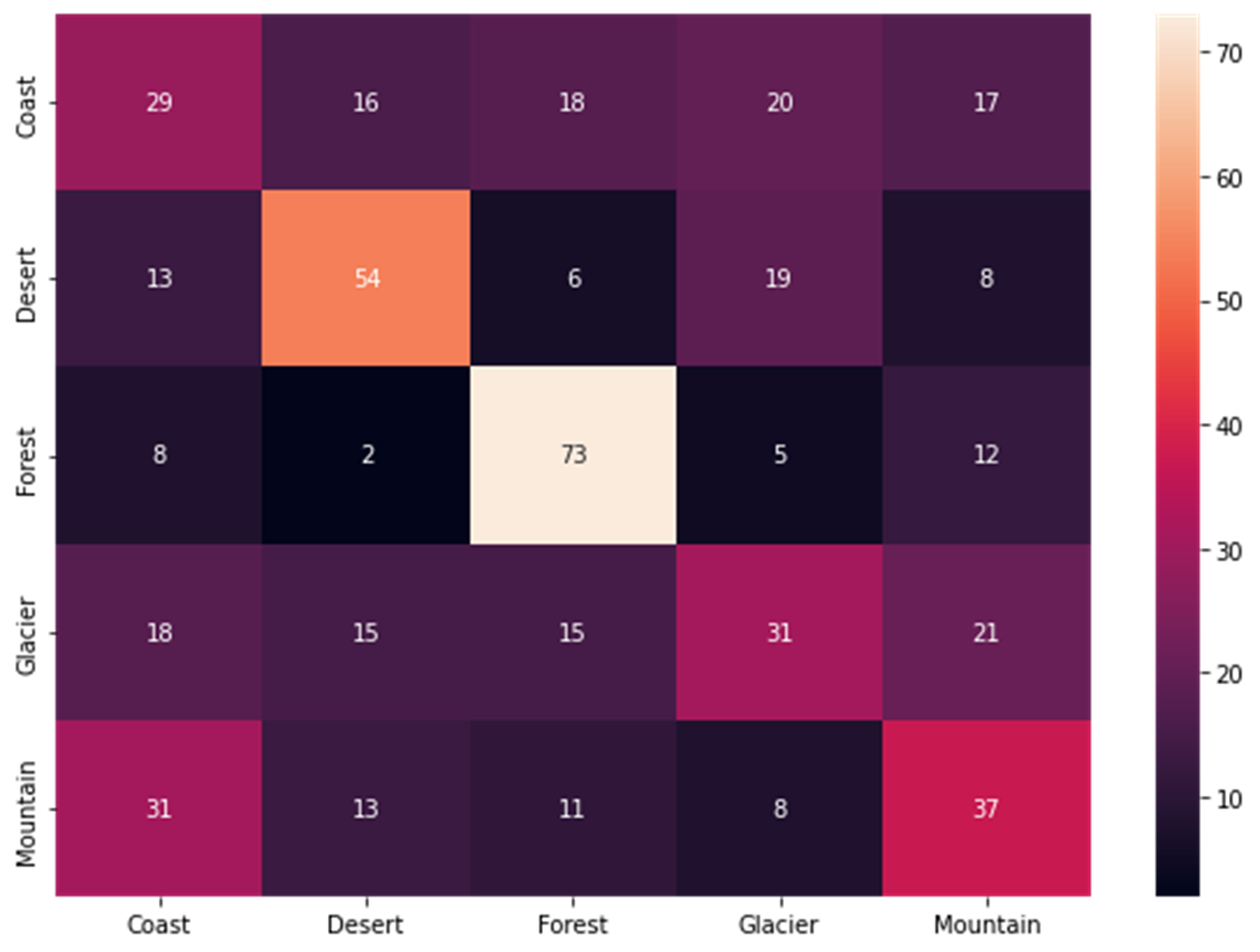 Confusion matrix for SIFT+ORB.
Confusion matrix for SIFT+ORB.Convolutional Conquerors
As the finals were fast approaching, I shifted my focus to neural networks. With limited time, I couldn't afford to train one from scratch, and frankly, I wasn't sure how best to approach it. However, I realized that convolutional neural networks produce an output vector that could potentially be used to measure the distance between images.
I thought, why not use a pre-trained neural network, "chop off its head", and simply utilize those vectors? So, I went ahead and acquired an EfficientNet without the classification layers, hoping to evaluate its potential... And it failed spectacularly, producing seemingly random vectors that made the images virtually incomparable.
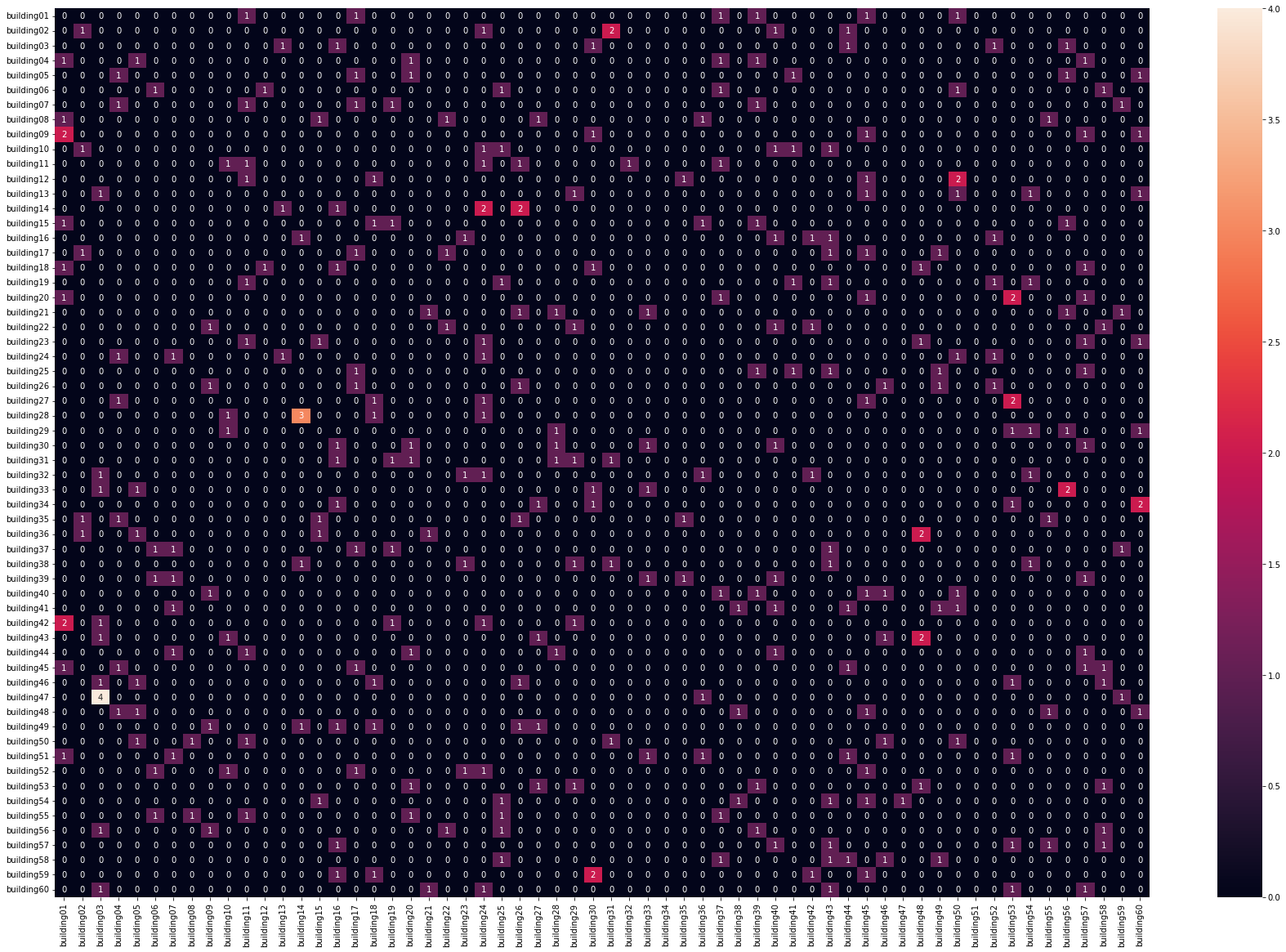
Convinced that the vectors were not random, but simply not comparable using standard distance measures, I tried to train a similarity-measuring neural network. A rather desperate move, I admit. In the end, the results were far from usable. The classifier consistently picked certain buildings while completely ignoring others, and that wasn't even the primary objective! So I decided to stop wasting time and let it go. I even experimented with machine learning techniques other than neural networks, such as Random Forests and KNN, but unfortunately these efforts were also fruitless.
With the project deadline looming and time running out, I was almost ready to throw in the towel. I wondered if maybe EfficientNet was to blame for my struggles. In a last-ditch effort, I decided to give the BiT-M R50x1 model a try and evaluate its performance. To my amazement, it worked like a charm on the first try! I achieved spectacular results with a remarkable 93% accuracy!
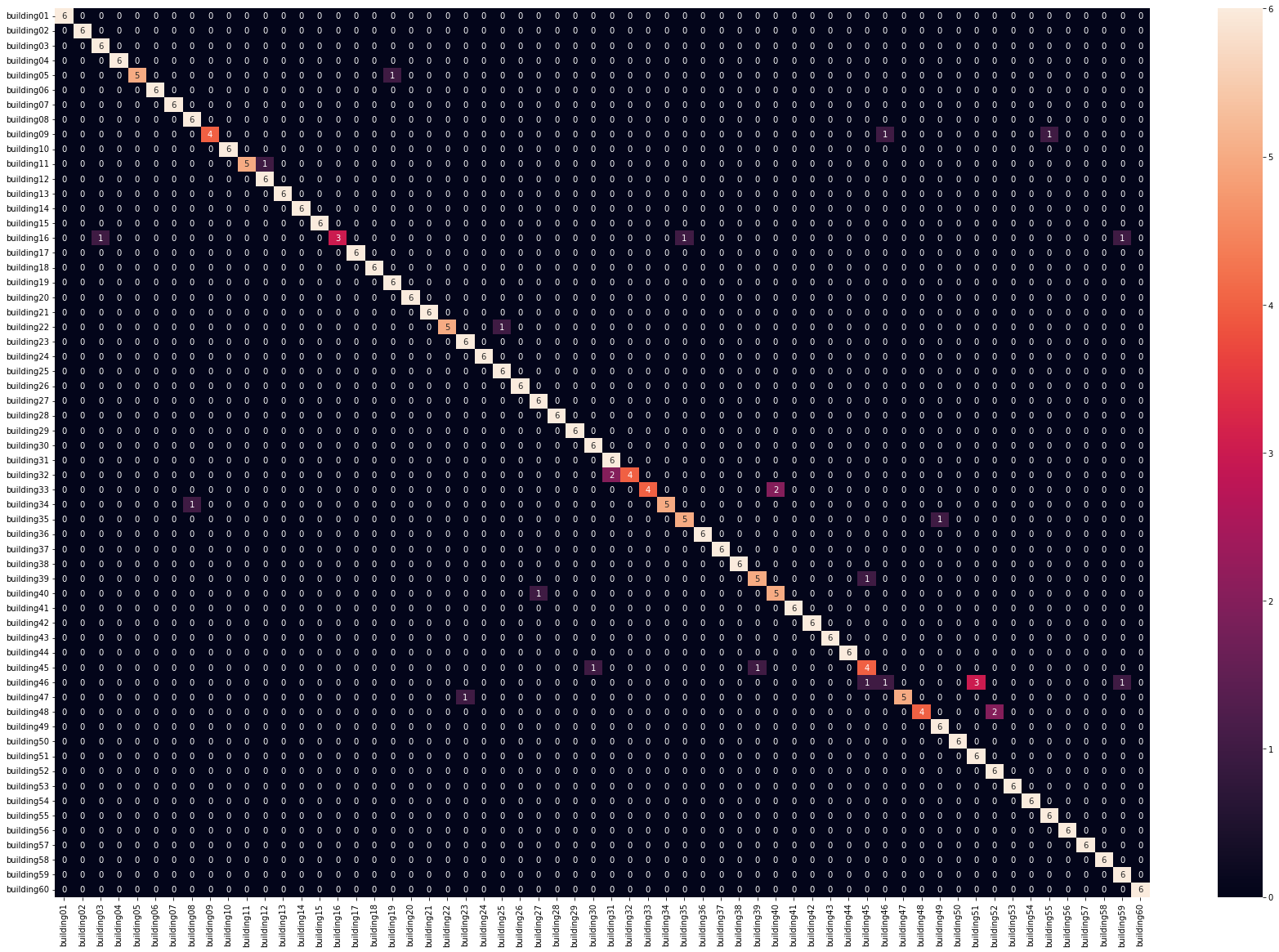
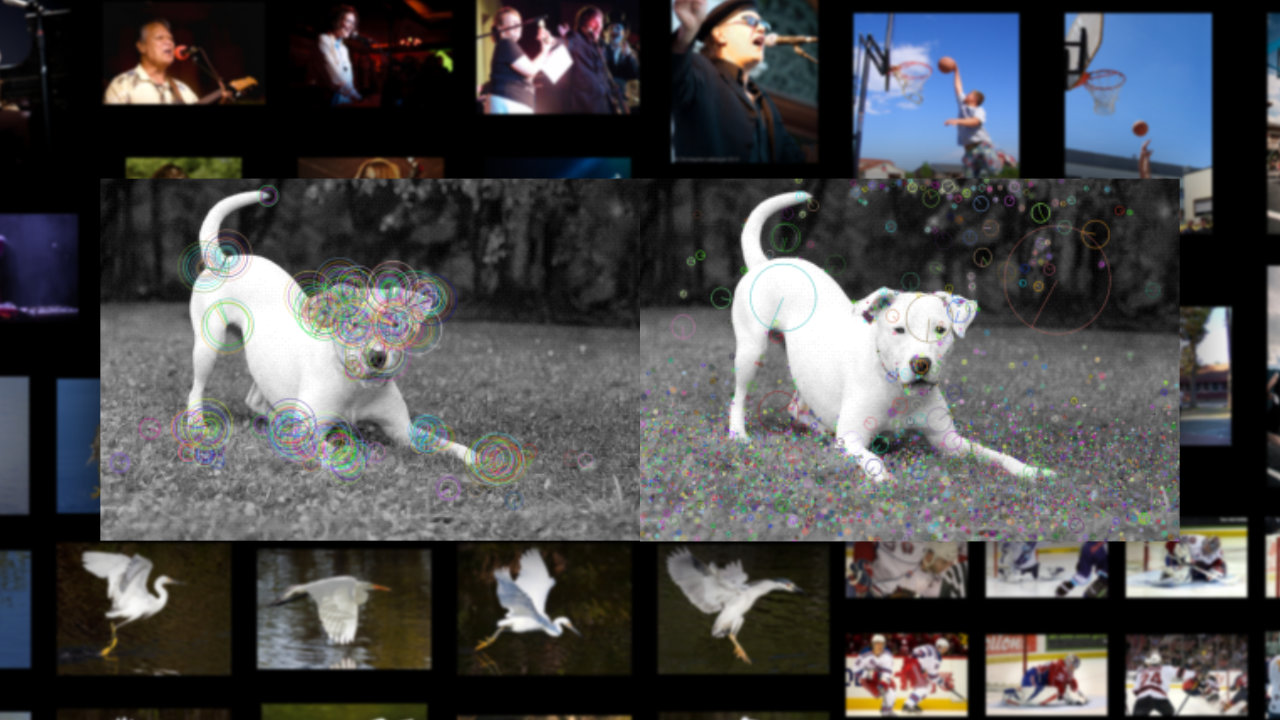
Thrilled by the impressive performance of the BiT-M model, I decided to test it on the entire Flickr30k dataset, intending to search across these vectors. After waiting patiently for a few hours as the model gradually processed all 30,000 images, I finally had my database. With great anticipation, I ran my first search and was blown away by the results! The images retrieved were not only visually similar to the query, but they also shared the same CONTENT.
 That's even the same dog in some of the pictures!
That's even the same dog in some of the pictures!

In conclusion, my journey into the world of content-based image retrieval has been nothing short of eye-opening. From exploring classic methods like color auto-correlograms, to diving into local features with SIFT and ORB, and finally delving into the power of neural networks, I've learned a great deal about the different approaches to CBIR.
Although I faced some challenges along the way, the remarkable success of the BiT-M model on the Flickr30k dataset was truly rewarding. It demonstrated the incredible potential of neural networks to retrieve images based not only on visual similarity, but also on content. As we continue to push the boundaries of what's possible with CBIR, the future of image search is undoubtedly bright and full of innovation.
I hope you've enjoyed joining me on this exciting journey and that you've gained some valuable insights into the fascinating world of content-based image retrieval.